
Enterprise Translation
Don’t trust your customer conversations to a default translation solution.
Unless you are okay with losing millions of dollars each year from misunderstandings.
by Heather Shoemaker
Table of Contents
With the growth of generative AI for seemingly infinite use cases, technologists are assuming that generative AI is good enough for business translations too. As a result, SaaS vendors are integrating untrained large language models (LLMs) as a default translation option in many business-critical platforms. It’s the same assumption folks made ten years ago when neural machine translation (NMT) models started to sound really fluent.
The truth? As with Google Translate in 2015, it depends on what you’re translating.
A default translation solution is always an out-of-the-box LLM, such as Chat GPT, Llama, and Gemini, or an NMT, such as Google, Amazon, and Microsoft. These solutions can generate highly fluent translations, provided that the content you’re asking them to translate is basic.
Just think of it like this: You wouldn’t plug ChatGPT into your CRM (Customer Relationship Management platform) and let it start answering customer support chats without any training. The same risks exist if you plug ChatGPT, Google Translate, or any single AI model into a business-critical system for translation and begin corresponding with your customers without ensuring it has the context to translate your company’s terminology accurately.
Without that missing context (i.e. training), you risk 30% of your communications to customers being misunderstood. That isn’t just a nuisance for your customers or your agents. It can result in significant financial losses in terms of agent time, brand perception, and customer loyalty. We analyzed a decade’s worth of real-time customer support translations using both LLMs and NMTs, and we discovered that mistranslations can easily result in a million-dollar problem.
At Language IO, we have been using AI for real-time, business-critical translations since 2011. Looking back on the substantial data we have generated over the years, we found some interesting trends that should concern you if you use a single model and/or an untrained mode (such as the default model embedded in your CRM) for your business translations.
First some background on LLMs (Large Language Models) and NMTs. While generative AI does much more than just translate content, using it for translation scenarios comes with the same set of challenges that we faced when we started using NMTs 14 years ago. No model – whether it’s an NMT or an LLM – will accurately translate the word “player” from English into Spanish if it doesn’t know whether you’re talking about a tennis player (jugador) or a video player (reproductor). “What’s the best player?” without context will be translated as “Cual es el mejor jugador” because folks talk more about sports players than video streaming players.
That does not make it the correct translation for a video streaming company. And that’s just a simple example. What about gaming platforms that make up words that have no literal translation? Take Abomination of Gudul. Magic the Gathering made up this English card name and reinvented it for each of the many languages the game supports. In Chinese, it is called “谷渡憎恨兽” but if you translate that back into English through ChatGPT or Google Translate, you will get “Gudu Hate Beast” from Google Translate or “Valley-Crossing Hatred Beast” from ChatGPT. Literal translations of made-up terms don’t work and never will, no matter how smart your LLM is.

Further, it’s not just about translating specific terms accurately for comprehension. It’s about fluency—or how human-sounding the translation is —availability and security. I will address each one in turn.
Lastly, before we dive into these four categories, business-critical platforms such as CRM systems that bake in a default translation solution do so for SMBs without a large global footprint and/or whose translation requirements are basic. These are still general models with no training, and you WILL wind up with a Gudu Hate Beast if you use them.
As we’ve seen with the over 100 Fortune 500 companies that partner with Language IO for their business translations, a single-model or default solution will not meet the standards you expect when engaging with your customers. Furthermore, these platforms bake in translation as an afterthought. It’s not their core competence. All we’ve done for 14 years is provide real-time multilingual support translations for the enterprise.
Fluency
A single model, whether it’s ChatGPT, DeepL, or anything else, will be limited in its ability to provide fluent translations for every language pair that a company supports because no single model exists that is the most fluent model for all languages. At Language IO, we realized years ago that we couldn’t marry ourselves to just one model for all the 150 languages we needed to support.
Instead, we developed proprietary machine learning that determines which is the most fluent model for a language pair on any given day. We call this Smart Model Selection, and it makes these decisions based upon proprietary supervised (human-in-the-loop) learning from users across our extensive customer base.
Smart Model Selection connects with the most fluent available model for any language pair on any given day. Even if you forget the term “Smart Model Selection,” the key is that we’re a multi-model solution that is not reliant on a single model. When working with real-time translation technology for your business, ensure you’re not committing to a single-model translation solution for fluency and availability reasons.
To demonstrate why this is so important, a bit of background. Language IO’s real-time translation technology plugs into CRMs, enabling language-agnostic support teams to chat with customers in whatever language the customer speaks. Below is a support chat that was recently sent to an English-speaking support agent in the travel industry from a Japanese customer who wanted to move up the return date of their flight.
To show the value of a multi-engine solution such as Smart Model Selection, we translated the Japanese support request into English using the Language IO platform – which selected the most fluent model available – and through a single, well-known commercial model. When a human linguist analyzed both translations, the linguist needed to alter the single-model translation by 71%, so it made sense. In contrast, they did not need to alter the Language IO translation at all. Our Smart Model Selection always knows which model is the most fluent model for Japanese-to-English translations on any given day. And yes, the most fluent model does change regularly.
Japanese Support Question:
帰りの便を少し早めることはできますあ。
Single Commercial Model:
You can speed up your return flight a little earlier.
Language IO:
Is it possible to move up the return date a little?

Accuracy
Availability
An equally important advantage of a many-model solution such as Language IO over a single-model solution is that when a model fails to respond or is very slow to respond —which happens regularly, even for the largest translation platforms in the world— a good multiple-model solution will fail over to the next most fluent model for that language pair. Whereas, if you are integrated with only a single model and it is not responding, you simply don’t get a translation.
The Language IO Smart Model Selection layer integrates with all the best commercial models – both NMTs and LLMs – that adhere to our zero data retention policy. This means that we don’t integrate with vendors that will hold onto the content you pass us for translation. When we call the most fluent model for the language in question, if that model is not responsive, we instantly fail over to the second-most-fluent model based on our network learning approach. From an availability perspective, this failover is critical. We have tracked our calls to these many commercial models over time and have found that even the world’s largest AI translation models fail to respond far more often than you would think. If your business-critical system only has access to a single model, you will experience outages when you receive no translations back.
The Language IO Smart Model Selection layer will also failover for quality reasons. Whenever we get a translation back from the selected model, we run a proprietary, similarity algorithm over the original message and the translated message to validate that the underlying meaning of the translation is a close match to the original message. If the semantic similarity between the translated and original message is too far apart, we automatically failover to the priority two models. Again, you might think that the quality of major commercial models will never tank. Oh, they will. The inner workings of neural models are often a mystery even to their makers. Some of the best-known AI translation solutions sometimes spew nonsense.
The graph below shows the output of semantic similarity from our Smart Model Selection platform for Japanese-to-English translations via one of the best known AI translation models in the world. As you can see, the model started generating nonsense – literal gibberish – at 18:15, and it didn’t improve until 19:41. If your business-critical operations were dependent on a single model, for an hour and a half, your translation output would not have been usable.
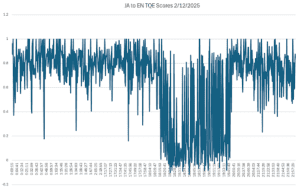
Language IO Quality is Up to Six Times Higher
The Cost of Lost Agent Time, Brand Reputation, and Customer Loyalty from Mistranslation
When dealing with your company’s mission-critical support communications, it’s no wonder that almost 30% of these messages would be mistranslated if you ran them through untrained ChatGPT or Google Translate… or any single untrained model.
But how does that impact your bottom line?
It does so most immediately by increasing the cost to serve by requiring more agent time. While it varies by company, a good Average Handling Time (AHT) for a support chat session is six minutes. Given that the most important chat messages in a session translated with a generic model will be mistranslated for lack of context, it’s safe to assume that the AHT for that session will at least double.
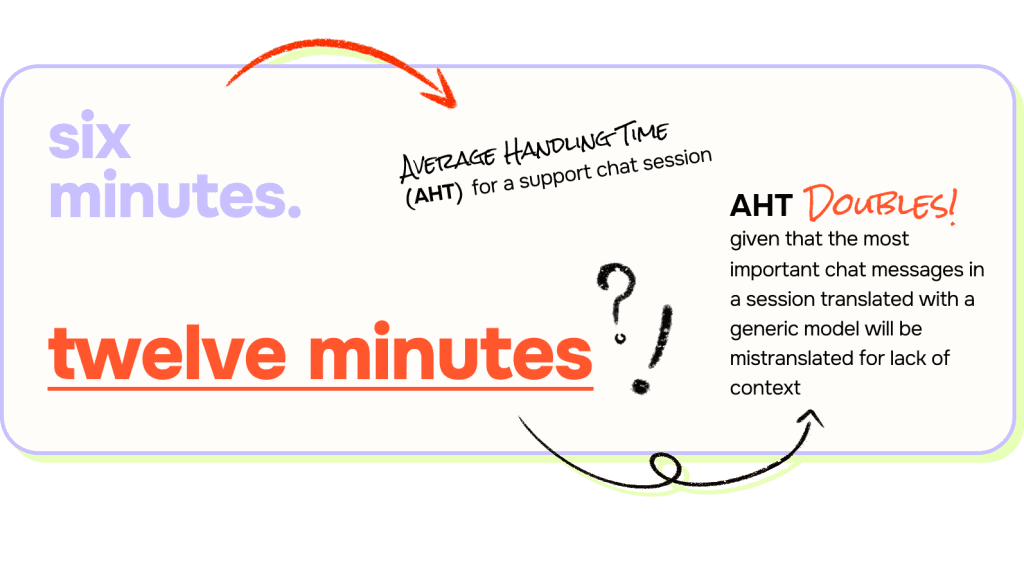
Realistically, the support session might need to be transferred to a native-speaking agent – if such an agent exists in your organization. But let’s assume that the first agent can muck through the process with bad translations and that it merely doubles your agent’s handle time for support sessions that require translation. We also know that the average cost to your company for a chat support session is $10 USD. If you are doubling the AHT, your translated sessions will double in cost from $10 USD to $20 USD.
That can add up to substantial expense. Our analysis indicates that the average, publicly traded B2C SaaS company will handle about 2,448 chat support sessions per day. Language IO data indicates that for some of our larger customers based in the US, at least 5% of their chat support sessions require translation. However, for European countries such as France and Germany, between 15% and 64% of their customers are international. Even if we are conservative and say that between the EU and the US, 10% of publicly traded, B2C SaaS company support requests will require translation, that amounts to 245 translated support sessions per day. If you double the cost of 245 chat sessions per day, a B2C publicly traded SaaS company that uses a single translation model solution with no context would wind up spending an additional $2,450 per day or about $900,000 USD a year owed to mistranslations.
And the above doesn’t even account for churn. The long-term costs are equally concerning. Research has proven that every negative interaction with a customer can increase churn risk. In fact, 49 percent of customers who left a brand to which they’d been loyal in the past 12 months say it’s due to poor customer experience, according to CX platform Emplifi. In today’s increasingly competitive and expensive customer acquisition landscape, introducing negative experiences poses a concerning risk—particularly for businesses with high Customer Acquisition Costs (CAC) and substantial Lifetime Value (LTV). When we take churn into consideration, that $900,000 price tag can quickly multiply into millions of dollars lost each year.

With each mistranslation doubling the time your agents need to spend on a support case and increasing the risk of churn or damage to your brand reputation, the answer to the question of whether a default, or embedded translation solution is clear. Do you want to double your average handle time, risk customer confusion, and increase churn or damage to your brand? Language IO customers have proven operational efficiencies are only achieved with fluent, accurate translations. Otherwise, you just introduce a negative customer experience and burn agent time.

NOTES
- In B2C companies you’ll see on average one support agent to 500 customers. The average public SaaS company has 36,000 customers, which means the average public SaaS company requires 72 support agents Given that healthy occupancy rates are between 85% and 90%, and it’s a well known stat that a single support agent can field 40 chat sessions a day, at the lower end of healthy occupancy we’re looking at each of those 72 agents fielding 85% of 40 chat sessions or 34 sessions for a total of 2,448 chat sessions a day.
- According to Live Agent, the average company has 578 tickets per day, 3,991 per week, and 17,630 per month. The ticket volume in working hours comes out to a total of 6,594.
- If we just use the averages from Live Agent there are 578 tickets a day which works out to 17,630 per month. These numbers can be higher or lower depending on if you are B2B or B2C or your industry. If 30% of calls require additional agent time, that impacts approximately 5,100 out of 17,000 case and now incurs an additional cost of $10 per ticket. This translates to a monthly cost of $51,000, so we are talking about a half-a-million-dollar problem ($612K) annually.


