Dedicated to safeguarding you and your customers
Our commitment to secure machine translation is reflected in the people, technologies, and processes that we employ.
We are the only vendor in the multilingual customer support market that is certified against the latest version of the ISO-27001 standard.
See how we protect you and your customers’ data



Global organizations trust Language I/O.






Table of Contents
A Commitment to Secure Machine Translation
Language I/O’s approach to security follows the industry standard. We take a risk-based approach to ensuring the confidentiality, integrity, availability, and privacy of our assets and services. We take special care to protect the personal data that flows through our systems from our clients because our greatest asset is our relationship with our customer. We are ISO 27001:2022 certified. You can download a copy of our ISO 27001:2022 certificate here. Language I/O is the only vendor in the multilingual customer support market that is certified against the latest version of the ISO-27001 standard – the 2022 version.
The Language I/O SaaS translation solution can be integrated into Client Relationship Management (CRM) platforms such as Oracle Service Cloud (OSC), Salesforce, Zendesk, and others for translation of incident/ticket content, article/answer content, and chat content. Our products enable monolingual support agents to provide customer support in any language. We also provide high-quality translation of informal, user-generated content (UGC) that is often rife with misspellings, abbreviations and other hard-to-translate terms. All translation requests passed from CRMs and API calls to the Language I/O server are processed and often sent to a third-party sub-processor for translation.
Data Flow
The flow of data through the system depends upon the translation service or services for which the customer is configured. Because Language I/O is plugged into many translation services, the data could flow into and out of several integrated systems. That said, our customers can drastically minimize the likelihood for a data security breach by adhering to our personal data policy.
Data Privacy
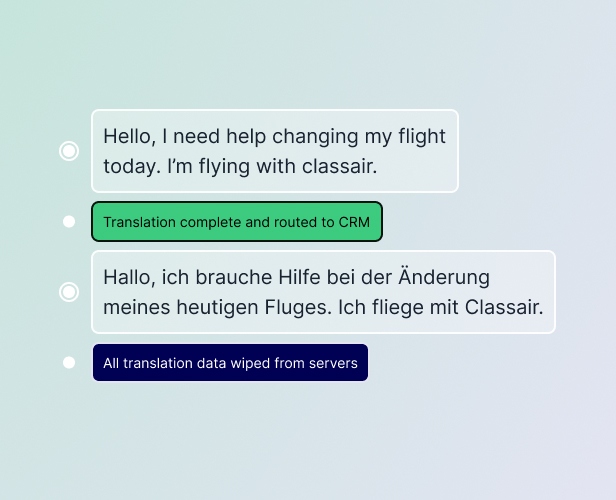
All data passed between the CRM and the Language I/O server, and between the Language I/O server and a translation service, travels via a secure, TLS 1.2-encrypted and authenticated connection. Because our customers pass UGC to us for translation, we assume that every translation request that comes from a CRM chat session or a ticketing system contains personal data per the GDPR definition. As soon as a chat or email hits our server for translation, we first scan that content for personal data and if we find any personal data, we encrypt and pseudonymize that information before it is passed to a subprocessor for translation. Once the translation is passed back into Language I/O, the personal data elements are decrypted and then passed back via API to the requesting process/party. Once the translation is passed back, both the translation and the original content sent to us for translation are scrubbed from our system and any subprocessor system.
The Language I/O platform regularly undergoes security audits administered by our CRM partners (Salesforce, Oracle, Zendesk) as well as by vendors and clients. We have quarterly penetration tests, weekly vulnerability scans and on-going intrusion prevention and detection. We comply with the European Union’s GDPR (General Data Protection Regulation) and have had this adherence, per our information security management system, audited and certified for compliance with the ISO 27001 standard. You can download a copy of our ISO 27001:2022 certificate here.
The Data We Store
While the Language I/O CRM integrations do have access to the incident/case, answer/article and chat session records, the apps do not pull from the associated customer contact or agent profile records. The data that is passed from the CRM to the Language I/O server includes only the data that the server requires to a, perform the translation and b, push translations back into the CRM correctly. None of the free-form, UGC from the customer or agent passed into our server for translation, which is part of cases, tickets, incidents or chats, is persisted in our database.
GDPR and CCPA
Language I/O’s technology is fully compliant with GDPR (General Data Protection Regulation) and has been since the regulation went into effect in May of 2018. In compliance with GDPR, Language I/O has performed the required Data Protection Impact Assessments on each of its products. Furthermore, when translating content from our customers’ CRMs, Language I/O never stores any personal data that might be embedded in the User Generated Content (UGC) sent to us for translation. Once the translation is pushed back to our customers it is neither stored in our database, log files, or elsewhere.
Additionally, Language I/O fully complies with all directives under the California Consumer Privacy Act (CCPA).
As part of the process to become ISO-27001 certified, a third party auditor has validated our GDPR and CCPA compliance.
PCI Compliance
Language I/O is committed to protecting consumer credit card data in compliance with the Payment Card Industry Data Security Standard (PCI DSS). Our alignment with this standard is reflected in the people, technologies and processes we employ.
We conduct regular vulnerability scans and penetration tests in accordance with the PCI DSS requirements for our business model. We attest to our PCI compliance annually, and our most recent self-attestation was completed in December 2023.
Privacy Policy
Language I/O adheres to the Privacy Shield Principles.



Our customers love us