
In the current no-code world where artificial intelligence handles repetitive tasks for us, one of the key technologies to help any solution improve is active learning. Active learning is a business must-have because it reduces costs and improves efficiencies over time. At Language IO, our R&D team loves working on solutions that incorporate ongoing learning seamlessly so that the human involvement from both our team and our customers is minimum from day one. Anything that can be automated should be automated.
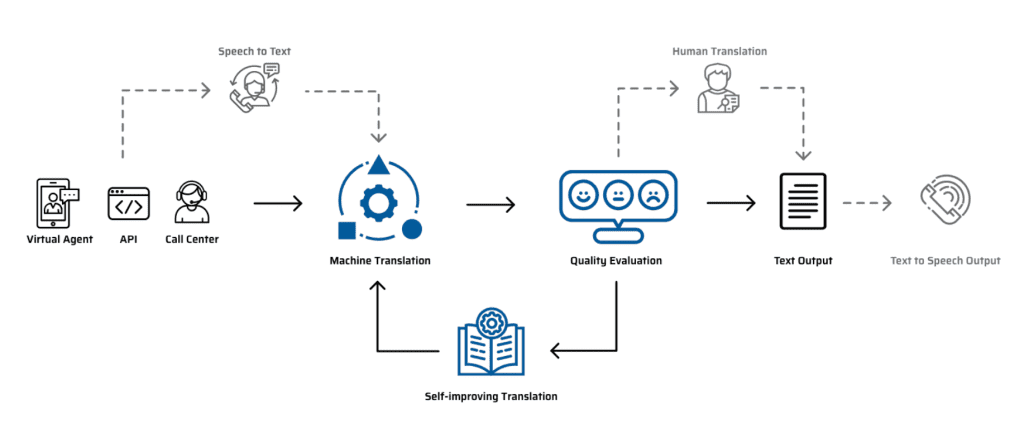
In the figure below, we show the key pieces of Language IO’s tech stack. As you can see in the center blocks, we select the best machine translation engine for each customer, after which we can evaluate the quality of the output. By learning from the annotations of the reviewers and other meta-data such as sentence complexity and customer-specific terms, we are able to design the active learning loop so that the MT quality improves over time.
Active learning can be achieved through a variety of solutions. The best approach depends on the business need, the language pair, and the content type, as well as the data assets owned by the customer, among others. What we often see is that while customers might have translation memories, they are not well-suited for chat and cases/tickets. The reason for this is that the language used by regular customers or agents vastly differs from that of structured branded content. Training a machine translation engine with article translation memories risks degrading the output of generic machine translation engines that account for all content types in their training data and adapt themselves to the content type with their attention mechanisms.
As you see, the process of training, evaluating, and continuously improving therefore has a high risk of failure.
What we often see is that while customers might have translation memories, they are not well-suited for chat and cases/tickets.
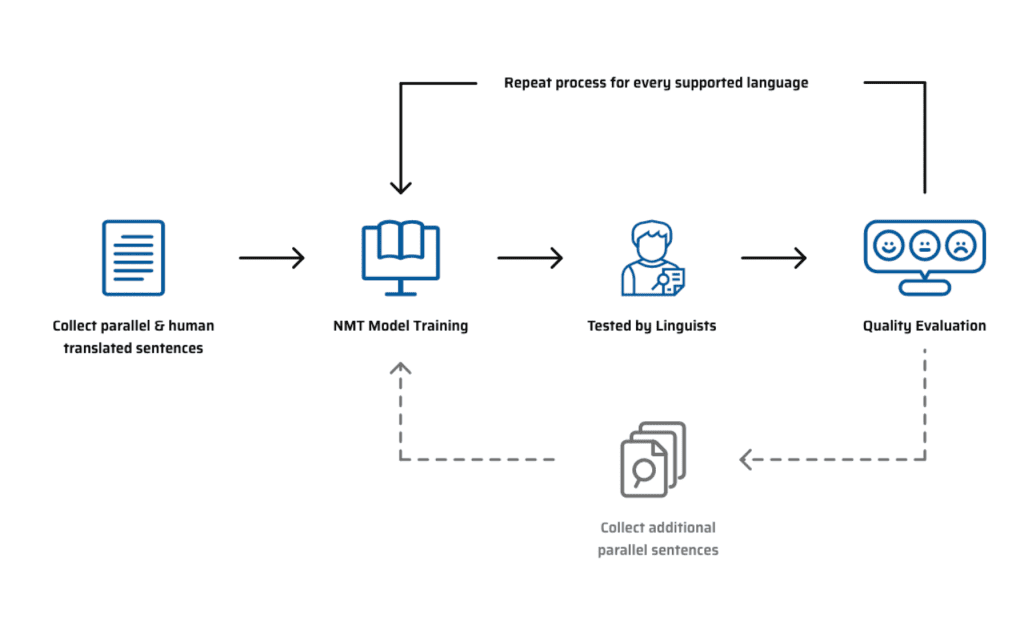
For details on how the neural machine translation training typically works, check the figure below. Data might be available off-the-shelf, or the customer might need to either collect or create data for their use case, which is in any case an expensive process. Once the MT engine is trained, testing is needed with automated and human metrics. This process will determine the need to improve the training data or approach or if the customer can release the model. The market price for this process is typically a few thousand dollars.
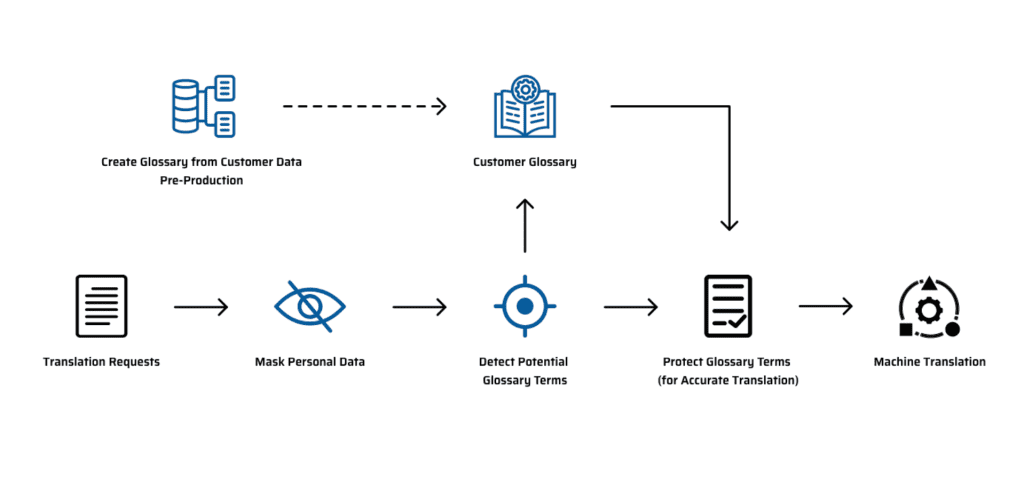
On the other hand, we can extract glossaries from those translation memories and also use the company’s glossaries for all the language pairs. These glossaries contain terms that are unique to the customer and relevant to their brand, which might or might not be translated. If we learn those terms in our translation process and then continuously add new terms in an unsupervised way, we’ll be able to ensure that the communication between agents and customers is fluent.
For details on the ongoing process to update customer terminology, please see the figure below. It’s important to note that for security and confidentiality purposes, we always protect personal data, so that it is never part of the glossary stored in our infrastructure. As for involvement from our customers, it can range from none to a human validation on their side for every term we propose.

Diego Bartolome
Chief Technology Officer at Language IO
Diego has been working for over 16 years at the intersection of languages and technology to help people and companies communicate in any language. He has built cohesive teams to create, improve, and scale tech products with a deep business impact both at his own start-up tauyou and at TransPerfect. Prior to Language IO, he worked on cognitive services (language, speech, vision, and decision) at Microsoft.


